TL;DR
Crawl-based ai for seo is about making pages reachable, readable, and trustworthy for AI crawlers as well as search engines. SaaS teams should focus first on site hierarchy, internal linking, server-accessible content, and evidence on commercial pages so AI systems can extract and cite the brand more reliably.
AI search visibility depends on whether machines can reliably crawl, parse, and trust a site’s structure. For SaaS teams, that means site architecture is no longer just an SEO concern; it directly affects whether a brand appears in AI-generated answers and receives attribution.
A simple definition is useful near the start: crawl-based AI for SEO is the practice of structuring a website so AI crawlers can access, interpret, and reuse its content accurately. That includes navigation, internal linking, page hierarchy, rendering, freshness, and evidence.
Why crawlability now affects both rankings and citations
Traditional SEO has always depended on discoverability. What changed is that more systems now sit between the page and the reader. Search engines still crawl and rank pages, but AI products also ingest, summarize, and cite information through their own crawl and retrieval layers.
According to ZipTie’s checklist for AI crawlability, technical SEO for AI crawlability includes configuring sites so bots such as GPTBot, ClaudeBot, PerplexityBot, and Google-Extended can parse content. That matters because these bots are not always operating with the same crawl patterns or priorities as Googlebot.
This is where the business case gets practical. If a pricing page, feature page, or comparison page is hard to reach, rendered inconsistently, or disconnected from supporting evidence, the brand may still rank in search while being underrepresented in AI answers. The result is a new visibility gap: impressions happen inside AI interfaces, but the brand is absent from the cited sources.
Lumar uses the term Generative Engine Optimization to describe this shift toward getting found and cited in AI search environments. Whether a team calls it GEO, AEO, or AI search optimization, the structural requirement is the same: machines need a readable site before they can trust its claims.
A useful point of view follows from that. Do not treat AI visibility as a prompt problem first. Treat it as a crawl and content architecture problem first. Prompt phrasing can influence output. It cannot compensate for pages that are difficult to discover, thin on evidence, or fragmented across the site.
For SaaS companies in particular, this change exposes a common weakness. Many sites are built around product navigation for humans but not around topic clarity for machines. Feature pages sit in one folder, templates in another, help docs on a subdomain, and use cases in a separate CMS with weak internal links. Humans can click around and infer the relationships. Crawlers cannot infer as much as teams assume.
That is why crawl-based ai for seo has become a practical operating concern in 2026. It sits at the intersection of organic growth, AI answer inclusion, attribution, and conversion.
What AI crawlers need from a SaaS website
Most teams overcomplicate this. AI crawlers do not need a clever content strategy deck. They need a site they can traverse cleanly and extract from with low ambiguity.
The simplest reusable model is the readable site architecture model:
- Reachability: important pages must be discoverable through links, not only search or scripts.
- Hierarchy: topics must sit in a clear parent-child structure.
- Clarity: each page must state what it is about in direct language.
- Evidence: claims need supporting details, examples, or references.
- Freshness: key pages need regular updates and visible maintenance.
This model is intentionally plain because plain structures are easier to execute.
Reachability matters more than teams expect
If a page is only accessible through on-site search, faceted navigation, or a JavaScript interaction that some bots may not process well, it is effectively hidden. Botify’s guidance on traditional and AI search bots explains that a new wave of AI crawlers is changing how content is ingested compared with traditional search bots. That means teams should not assume parity between what Google sees and what every AI system will use.
A clean crawl path usually looks like this:
- Homepage to solution category
- Solution category to feature or use-case page
- Feature page to related documentation, pricing, templates, and proof pages
- Blog articles to commercial pages and back again through relevant context
This is also where internal links carry more weight than many editorial teams give them. A feature page with ten relevant inbound links from cluster content is easier to discover and easier to classify than a page isolated behind top navigation alone. For teams building out product-led authority, this is similar to the structure described in our guide to LLM-ready feature pages, where extractable page design matters as much as traditional on-page optimization.
Hierarchy reduces extraction errors
Machines do better when each directory and page type has a job. For example, /features/, /use-cases/, /integrations/, /compare/, and /blog/ each signal a different intent. That does not mean every site needs that exact setup. It means the information architecture should express relationships explicitly.
Weak hierarchy creates three recurring problems:
- Duplicate topical coverage across page types
- Conflicting definitions and positioning language
- Important pages buried too deep in the site
A practical rule is that revenue-relevant pages should usually be reachable within a few clicks from the homepage and connected through contextual links from supporting content. When a crawler can move from an article about AI search visibility to a feature page, then to a trust or proof page, the brand narrative becomes easier to assemble.
Clarity beats cleverness on the page
Many SaaS pages are still written like ad copy. That is a conversion issue and a crawl issue. Pages full of abstract headlines, hidden copy blocks, tabbed content, and vague claims leave machines with little extractable substance.
Clear pages tend to share a few characteristics:
- A direct headline that names the feature, use case, or topic
- A short definition near the top
- Scannable subheads that answer likely questions
- Plain-language summaries under each section
- FAQ blocks that mirror conversational queries
For a deeper explanation of why trust and extractability now overlap, the same principle appears in our content trust guide: the easier a claim is to verify and quote, the more likely it is to be reused in AI systems.
The pages that deserve the strongest architecture first
Not every URL should get the same treatment. Teams usually get better returns by fixing the pages that shape both revenue and machine understanding.
The priority stack is usually:
- Homepage
- Product and feature pages
- Use-case and industry pages
- Pricing and comparison pages
- Help center or knowledge base hubs
- High-intent blog articles that support commercial topics
This ordering follows the actual path many users now take: impression inside an AI answer, citation, click, page evaluation, conversion.
A concrete rollout example for a SaaS site
Consider a mid-market SaaS company with these baseline conditions:
- Product pages live under
/product/ - Use-case pages exist but are not linked from feature pages
- The help center sits on a separate subdomain
- Blog articles drive traffic but rarely link to commercial URLs
- Pricing is crawlable but thin, with little supporting context
The intervention is not a redesign first. It is an architectural cleanup:
- Move core product topics into a clearer taxonomy such as
/features/and/use-cases/if the current structure is ambiguous. - Add contextual links between every feature page and the two or three most relevant use cases.
- Link high-intent blog posts to the matching commercial pages using descriptive anchor text.
- Create hub pages that summarize each category before linking deeper.
- Expand pricing and comparison pages with definitions, constraints, and evidence.
- Audit rendering, broken links, and orphaned pages with Screaming Frog SEO Spider.
The expected outcome over a 60- to 90-day window is not a guaranteed traffic spike. The more realistic expected outcome is improved crawl coherence, clearer topical signals, stronger internal equity flow, and better inclusion of the brand’s pages in AI answer source sets. Teams should measure baseline crawl discoverability, indexed page health, AI answer mentions, assisted conversions from organic landing pages, and citation frequency before and after the rollout.
That proof shape matters. When hard numbers are not available up front, the right move is to define a measurement plan instead of inventing results.
What to measure before touching the architecture
A sensible baseline includes:
- Number of orphaned or near-orphaned commercial pages
- Internal links pointing to top commercial URLs
- Click depth for priority pages
- Share of pages with a direct query-matching H2 or FAQ block
- Visibility in AI products for a fixed prompt set
- Organic entrances to feature, pricing, and use-case pages
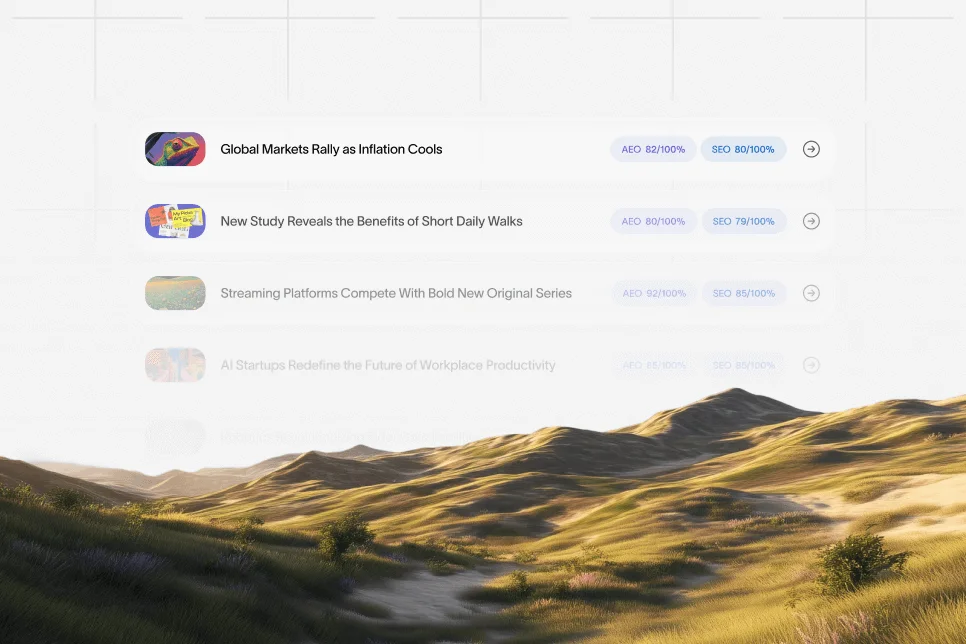
This is one place where a platform like Skayle can fit naturally. For teams trying to improve rankings and appear in AI-generated answers, the useful question is not just whether content exists, but whether the right pages are being discovered, cited, and kept current within one visibility system.
The 7-point cleanup checklist that makes pages easier to read
Teams looking for a practical starting point can use the checklist below. It is specific enough to act on, but broad enough to apply across most SaaS sites.
1. Remove orphan pages from the commercial layer
Every feature, use-case, integration, pricing, and comparison page should have at least one static internal link from a crawlable parent page. If the only route is XML sitemap discovery, the page is weaker than it should be.
2. Reduce unnecessary click depth
Important pages should not sit five or six layers deep. A crawler budget is not infinite, and deep pages are easier to deprioritize. Colorado State University’s overview of SEO in the AI era notes that crawl frequency is influenced by page importance, popularity, and update cadence. Deeper, lightly linked pages send the wrong importance signal.
3. Make category pages do real work
Many hub pages are thin collections of cards. That is a missed opportunity. Category pages should define the topic, summarize the subtopics, and direct both users and bots to the most important child pages.
4. Keep key content server-accessible
Teams do not need to turn every modern website into plain HTML, but they should ensure core copy is accessible without depending on fragile rendering paths. ZipTie’s AI crawlability checklist specifically calls out server-side rendering as relevant for AI bots. The practical takeaway is straightforward: if essential content loads late or inconsistently, some crawlers may miss it.
5. Add answer-ready blocks to high-value pages
A feature page should not stop at a hero and a list of benefits. It should include direct definitions, use cases, limitations, and FAQs. The page should contain passages that could be quoted accurately in an AI answer.
6. Consolidate duplicate intent
Do not split the same topic across three weak pages just to target slight keyword variations. One strong, well-linked page with clear supporting sections is usually easier to rank and easier for AI systems to cite.
7. Refresh pages on a schedule tied to business value
Pages that influence buying decisions should have a refresh cadence. Common Crawl’s write-up on AI optimization and Search 2.0 highlights how open web crawl repositories feed LLM analysis. That broadens the value of freshness: updates can matter not only for live search, but also for the web data ecosystems that shape future AI outputs.
Common architecture mistakes that block AI extraction
The biggest mistakes are usually structural, not advanced.
Mistake 1: treating navigation as the whole architecture
Global navigation helps users. It is not enough on its own. AI systems understand sites better when the topical relationships are repeated in-body through contextual links, explanatory hub pages, and supporting content paths.
Mistake 2: hiding substance behind design patterns
Tabbed interfaces, accordions, and interactive modules can be useful. But when the most important definitions, evidence, and differentiators are tucked into elements that are hard to render or easy to skip, extraction quality drops.
This is also where design and conversion intersect. Pages built for crawl-based ai for seo should not become ugly documentation pages. They should become clearer buying pages. Strong information scent usually improves both machine readability and human confidence.
Mistake 3: publishing disconnected content across multiple systems
A frequent SaaS pattern is a marketing site on one CMS, docs on another domain, community posts elsewhere, and changelogs with no linking logic. The brand knows these pieces belong together. Crawlers see fragmented authority.
The fix is not always consolidation. Sometimes the right answer is a stronger linking layer, consistent terminology, and clearer ownership of each page type.
Mistake 4: optimizing only for Googlebot
This is the contrarian position that matters: do not assume Google indexing equals AI readability. Google may render and understand a page well enough to rank it. Another AI crawler may parse a more limited version, hit access issues, or rely more heavily on plain structure and direct phrasing.
This does not mean chasing every bot with separate playbooks. It means building resilient pages that remain understandable under less forgiving crawl conditions.
Mistake 5: leaving proof off commercial pages
Brands often save evidence for case studies and leave money pages full of generic claims. That is backwards. The pages most likely to earn citations and clicks should include specifics such as supported use cases, constraints, workflow details, source references, and FAQs.
For teams working on broader AI visibility, our case study roundup on GEO results is useful context because it shows why visibility must be measured across answer engines, not inferred from one ranking report.
How to build an AI-readable content path from article to conversion
The most effective sites create a path, not a pile of pages. The path should support four moments: discovery, extraction, click, and conversion.
Start with the query families that shape commercial intent
For SaaS teams, those usually include:
- What the product category is
- How a specific feature works
- Who the product is for
- How it compares with alternatives
- How pricing or packaging works
Each family should map to a page type. When one page tries to do all five jobs, it often does none of them well.
Connect informational and commercial intent deliberately
A blog article about AI crawlability should naturally connect to feature pages, content trust pages, and solution pages. A feature page should return the favor by linking to educational material that gives the claim depth.
This is how authority compounds. Instead of isolated URLs competing for attention, the site presents a structured body of evidence.
Use page elements that help both readers and crawlers
The following page components tend to work well:
- Short definition paragraphs near the top
- Section summaries in 40 to 80 words
- Tables or bullet lists for comparisons
- FAQ blocks that match conversational phrasing
- Clear headings that mirror likely search intent
- Descriptive internal anchors and related-page links
Zeo’s guide to AI crawlers and SEO also discusses managing the SEO impact of bots such as GPTBot and ClaudeBot. The practical lesson is that access and readability decisions should be intentional, not accidental.
Instrument the right outcome, not just traffic
Traffic alone misses the new funnel. Teams should monitor:
- Inclusion in AI answer sets for target prompts
- Citation share relative to competitors
- Click-through from cited pages
- Conversion rate from AI-assisted landings
- Crawl health for commercial URLs
- Refresh rate on pages tied to revenue
That is the difference between content production and visibility operations. It is also why teams increasingly want reporting tied to action, not disconnected dashboards.
FAQ: What teams usually ask about crawl-based AI SEO
Does crawl-based ai for seo mean optimizing for every AI bot separately?
No. The practical goal is to make core pages broadly accessible, clearly structured, and easy to extract from. Teams should understand major bot behaviors, but the best long-term move is to build resilient site architecture rather than maintain a fragmented playbook for every crawler.
Should a SaaS company move its documentation onto the main domain?
Not always. A separate docs environment can still work if linking is strong, terminology is consistent, and important concepts are connected back to commercial pages. The problem is not the subdomain by itself; the problem is authority fragmentation without a clear crawl path.
How important is JavaScript rendering for AI visibility?
It matters when key content depends on it. If essential definitions, proof points, or links appear only after client-side rendering, some bots may not process the page as fully as intended. That is why server-accessible core copy remains the safer default.
What pages should be fixed first?
Start with pages closest to revenue and citation value: feature pages, use-case pages, pricing, comparisons, and the hubs that link to them. Then connect supporting blog content and help content so the full topical graph becomes easier to crawl.
Can better architecture improve conversion as well as AI citations?
Usually yes. Clear hierarchy, direct headings, stronger proof, and better internal paths reduce user friction. The same changes that make a page easier for machines to parse often make it easier for buyers to evaluate.
The pages that win are the ones machines can trust
The main lesson from crawl-based ai for seo is not that brands need more pages. It is that they need a more legible site. Reachable pages, direct language, supporting evidence, and consistent internal paths give search engines and AI systems something they can reliably use.
For SaaS teams, that creates a compounding effect: better crawlability improves discoverability, cleaner extraction improves citation potential, and stronger page clarity improves conversion once the click arrives. The site stops behaving like a collection of assets and starts behaving like a ranking and citation system.
Teams that want to operationalize this should begin with an architecture audit, define baseline visibility and citation metrics, and fix the commercial layer before expanding content production. If the goal is to measure AI visibility, understand citation coverage, and connect content execution to ranking outcomes, Skayle can support that process without turning the work into another fragmented toolchain.
References
- Technical SEO for AI Crawlability: The Complete Checklist
- Lumar | Website Optimization Platform | SEO, GEO, A11y & More
- Strategies for Traditional and AI Search Bots
- Screaming Frog SEO Spider Website Crawler
- State of SEO in the AI Era - CSU Social Media Blog
- AI Optimization Is Here: Are You Ready for Search 2.0?
- AI Crawlers and SEO: Optimization Strategies for Websites | Zeo
- AI Web Crawlers for SEO: How Bots Index Your E- …