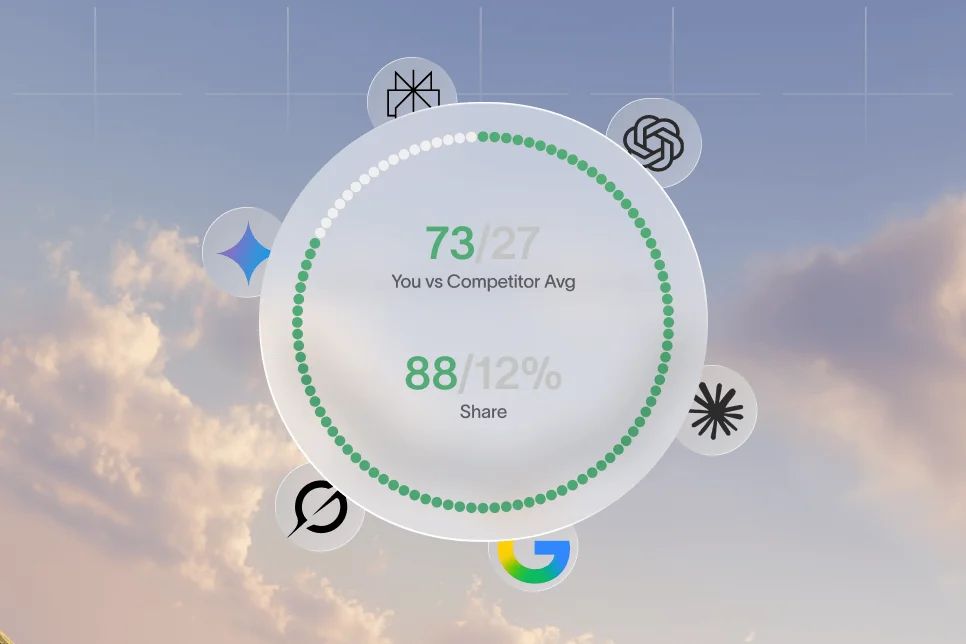
TL;DR
Developer docs often disappear from AI answers because they are hard to crawl, parse, and segment, not because the content lacks value. These five Technical SEO fixes focus on crawl access, HTML visibility, page structure, internal linking, and intent alignment so documentation is easier to extract and cite.
Developer documentation often ranks poorly in AI answers for reasons that have little to do with content quality. In many cases, the problem is structural: the pages are hard to crawl, hard to parse, and hard to extract accurately.
Technical SEO now affects more than search engine rankings. As Semrush explains in its technical SEO guide, modern technical SEO increasingly determines whether systems can crawl, render, index, and even cite a page in AI-generated results.
A simple way to frame the problem is this: if an AI system cannot reliably find the right page, isolate the right section, and interpret the answer cleanly, your documentation will be ignored or misquoted.
Why strong documentation still disappears in AI answers
Technical SEO is the practice of improving a site’s technical foundation so search systems can find, understand, and index pages effectively. Ahrefs describes technical SEO as work that helps search engines find, crawl, understand, and index content, which is exactly where many documentation sites fail.
Developer docs create a special kind of visibility problem.
They are often deep in the site tree. They rely on JavaScript-heavy navigation. They generate many similar URLs across versions, parameters, and language variants. They bury key answers inside tabs, accordions, or dynamically loaded panels. Humans can still navigate that. AI systems and crawlers often struggle.
This matters now because the funnel has changed. The path is no longer just impression to click. For documentation, the path is often impression -> AI answer inclusion -> citation -> click -> product evaluation.
If a company loses the citation step, it loses the qualified visit before the buyer ever reaches the site.
The practical stance is straightforward. Do not treat documentation as a publishing afterthought. Treat it as a structured knowledge asset designed for retrieval, extraction, and citation.
That is also where many teams misdiagnose the problem. They assume the issue is that AI systems “do not like” technical content. The more common issue is that the site presents the content in ways that are difficult to crawl and segment.
A useful review process is a documentation extraction audit:
- Check whether important docs URLs are crawlable.
- Check whether critical answers exist in static HTML.
- Check whether the page structure clearly separates topics and subtopics.
- Check whether internal links expose the depth of the documentation set.
- Check whether each page matches a clear user intent.
That five-part review is simple enough to repeat every quarter and specific enough to catch most structural failures.
For teams trying to connect these fixes to broader visibility work, this usually sits alongside content maintenance, internal linking, and AI visibility tracking. Skayle fits naturally here as a platform that helps companies rank higher in search and appear in AI-generated answers, especially when teams need one system to connect content updates, SEO execution, and AI visibility measurement.
1. Fix crawl blockers before rewriting a single paragraph
The first failure point is basic discovery. If crawlers cannot reliably access the documentation, nothing else matters.
According to Google Search Central documentation, controlling how bots crawl and index a site is a foundational technical task. That is especially relevant for docs environments, where versioned pages, filtered views, and duplicate routes can multiply quickly.
TechnicalSEO.com also highlights technical elements such as HTTP header responses and XML sitemaps as core discovery signals. For documentation sites, those signals are not optional housekeeping. They are part of retrieval infrastructure.
What usually goes wrong
Common crawl blockers in documentation include:
- Orphaned docs pages with no internal links from primary navigation
- XML sitemaps that exclude docs subdirectories
- Incorrect canonical tags across versioned pages
- Noindex directives left behind from staging workflows
- 302 chains and inconsistent redirects between old and new doc URLs
- Soft 404s on archived endpoints or deprecated reference pages
- Header responses that vary unpredictably by user agent or locale
These are routine issues, but they have outsized impact because docs content is often already several clicks deep.
What to audit first
A practical first pass should cover:
- Response codes for top-level docs hubs and key reference pages
- Presence of docs URLs in XML sitemaps
- Robots directives on current, deprecated, and versioned pages
- Canonical logic between versions such as /v1/, /v2/, and latest
- Redirect behavior when old endpoints or renamed pages are requested
A useful before-and-after pattern looks like this:
- Baseline: Important API reference pages exist but are not included in the XML sitemap, and old docs redirect inconsistently.
- Intervention: Add docs sections to the sitemap, clean redirect chains, remove accidental noindex tags, and standardize canonical handling.
- Expected outcome: More complete discovery of documentation URLs and fewer indexing conflicts within one to two crawl cycles.
- Timeframe: Review initial indexation and crawl behavior within 2 to 6 weeks, depending on site size and crawl frequency.
The contrarian point here is simple: do not start by rewriting copy. Start by making the pages reachable and indexable. Teams often burn weeks improving wording on pages that bots still cannot process correctly.
2. Put critical answers in the HTML, not behind interaction layers
The second problem is extractability. AI systems can only quote what they can reliably read and segment.
Many documentation teams unintentionally hide the most valuable content behind tabs, expandable panels, client-side rendering, or interactive code widgets. This may be acceptable for user experience in moderation, but it becomes a visibility problem when the primary answer is not exposed cleanly in the page source.
That is why technical SEO for docs is no longer just about indexing. It is about answer accessibility.
Pages that look complete but extract poorly
A page can appear excellent to a product team and still fail for AI extraction if:
- The summary is injected after page load
- Authentication requirements block documentation previews
- The endpoint description appears only inside a collapsed component
- Error explanations are hidden inside tabbed interfaces
- Parameter definitions are rendered inconsistently across similar pages
- The page relies on heavy client-side rendering before meaningful content appears
This is where teams should remember that a parser does not browse like a developer.
The practical standard for AI-readable docs
Every important docs page should expose three things in static, clearly labeled page content:
- A short definition of what the endpoint, SDK function, or feature does
- A concise explanation of when to use it
- A structured list of inputs, outputs, errors, or constraints
Those sections make extraction easier because they create answer-ready blocks. They also improve the chances of appearing in both search snippets and AI-generated summaries.
A concise paragraph of 40 to 80 words near the top of a page often does more for citation than an elaborate interactive layout further down.
As teams update docs templates, they should standardize this pattern across the site. This is also where our guide to scaling SaaS content becomes relevant: standardization is what keeps quality consistent when content volume increases.
3. Make page structure obvious enough for machines to segment correctly
The third issue is semantic structure. AI systems need help identifying where one answer starts and where another ends.
Ahrefs’ technical SEO guide emphasizes that technical SEO helps engines understand a page, not just find it. For documentation, that means headings, section order, labels, and content hierarchy directly affect whether extraction is accurate.
What clean segmentation looks like
A strong docs page usually includes:
- One clear page topic
- A precise H1 equivalent in the rendered page
- Predictable H2 and H3 sections
- Short answer-first paragraphs under each section
- Stable anchor links for important subsections
- Lists or tables that separate required fields, optional fields, and examples
By contrast, extraction gets worse when pages mix changelogs, reference content, troubleshooting, and marketing copy in one long surface.
A reusable structure for docs pages
A practical page pattern looks like this:
- What it is — a one-paragraph definition
- When to use it — the user intent or scenario
- How it behaves — key fields, limits, or outputs
- Common errors — issues and resolutions
- Related endpoints or guides — supporting internal paths
This is not a gimmicky framework. It is just a repeatable way to make a page segmentable.
Here is a realistic example.
- Weak version: A page starts with a long product intro, then shows a code sample, then places the endpoint meaning halfway down, with errors buried in tabs.
- Improved version: The page opens with a two-sentence description, then a labeled request section, response section, errors section, and related guides section.
- Expected outcome: Higher likelihood that AI systems extract the definition and use case correctly, rather than lifting an isolated code sample or ambiguous fragment.
This structure also improves answer quality for humans. A developer scanning for a rate limit or authentication requirement benefits from the same clarity that helps AI retrieval.
4. Build an internal linking path that exposes the full documentation set
Documentation is often invisible because the site architecture is too thin. Important pages exist, but crawlers have no obvious path to them.
WebFX’s overview of technical SEO notes that internal links and site architecture are core backend optimizations for discovery and usability. On documentation sites, that matters more than many teams realize because docs are naturally hierarchical and often very deep.
Internal linking failures common in docs
Typical problems include:
- Navigation exposes only category hubs, not key subpages
- Related endpoint links are missing from individual docs pages
- Versioned docs create dead ends with no bridges to updated pages
- Troubleshooting articles are isolated from the reference pages they support
- Guides and reference content live on separate subdomains with weak linking between them
These failures reduce crawl depth, but they also weaken contextual understanding. If a crawler cannot see how authentication, rate limits, webhooks, and errors connect, it has less context for interpreting each page.
A numbered checklist that catches most architecture issues
- Link every key docs page from at least one indexable hub.
- Add related links between concept pages, guides, and API reference pages.
- Surface latest-version pages clearly while preserving access to archived versions.
- Use descriptive anchor text, not generic “learn more” links.
- Add breadcrumb paths that reflect topic hierarchy.
- Include HTML navigation paths for critical docs sections, not only JavaScript-based menus.
- Review orphaned pages quarterly.
A useful mini case study format for teams is simple:
- Baseline: Authentication and webhook pages receive little organic traffic despite strong product demand.
- Intervention: Add links from the getting started guide, error-handling pages, and endpoint references; create a docs hub that surfaces the most cited topics.
- Expected outcome: Better crawl flow, clearer topic relationships, and stronger visibility for commercially important docs pages over the next one to two quarters.
- Measurement plan: Track impressions, indexed pages, and assisted conversions from documentation entrances in Google Search Central-aligned reporting practices and internal analytics.
For teams already reviewing authority decay, this work pairs well with a content refresh process, especially when old docs and support content compete with newer versions.
5. Match documentation to real intent instead of treating all pages as reference pages
The fifth issue is relevance. Technical fixes improve access, but they do not solve weak intent alignment.
That point has become more important as AI answer systems choose sources based not just on crawlability, but on usefulness and specificity. Search Engine Land’s reporting on intent alignment makes the core argument clearly: technical fixes alone cannot rescue weak relevance signals.
Why docs lose citations even when they are indexable
A page may be technically sound and still fail because it does not answer the actual query pattern.
For example:
- A user asks how to authenticate with an API using OAuth, but the page is a broad product overview.
- A buyer asks for webhook retry behavior, but the docs page only lists payload fields.
- A developer asks for a rate-limit explanation, but the page offers only code examples with no plain-language summary.
In each case, the issue is not access. It is intent mismatch.
The fix is content alignment, not just technical cleanup
High-performing docs content usually splits intent into separate page types:
- Reference pages for exact endpoint or method details
- How-to guides for workflows and setup
- Troubleshooting pages for error states and failure recovery
- Concept pages for architecture, limits, and policies at a high level
That separation matters because AI systems prefer answerable surfaces. A page trying to serve every intent often serves none of them well.
The strongest contrarian position in documentation SEO is this: do not force every important topic into API reference format. Build distinct pages for distinct intents.
That usually leads to better extraction, better citations, and better conversions because the reader lands on a page that matches the job they are trying to complete.
When this discipline is applied across a broader content estate, teams can also measure whether they appear in AI-generated answers, not just Google rankings. That is where visibility tooling matters. A platform like Skayle is useful when a company wants to measure AI citation coverage alongside rankings and content execution, rather than treat those as separate workflows. Teams that want a broader view of this shift can also review our AI visibility audit guide.
The mistakes that keep technical SEO work from paying off
Most documentation teams do not fail because they ignore technical SEO entirely. They fail because they fix the wrong layer first.
Mistake 1: Treating design polish as discoverability
A documentation redesign can improve usability and still reduce extractability if it hides key answers inside interactions or weakens HTML structure.
The right test is not whether the page looks modern. The right test is whether the answer is visible, crawlable, and segmentable without user interaction.
Mistake 2: Consolidating pages too aggressively
Teams often merge several intent types into one “ultimate” docs page. That can reduce duplication, but it can also blur meaning and make section extraction unreliable.
A cleaner approach is controlled separation with strong internal links.
Mistake 3: Letting versioning create duplicate noise
Versioned docs are necessary, but they need explicit handling. Without consistent canonicals, archive labeling, and latest-version pathways, crawlers waste attention on duplicate or stale surfaces.
Mistake 4: Measuring clicks only
The modern documentation funnel starts earlier. Teams should review:
- Search impressions to docs pages
- Inclusion in AI-generated answers where measurable
- Citation frequency for branded and non-branded technical queries
- Click-through rates from documentation entrances
- Assisted signups, demos, or product-qualified visits tied to docs sessions
Mistake 5: Assuming AI systems can infer context from code alone
Code samples help, but they rarely replace a clean natural-language explanation. If the page does not explicitly state what something does, when to use it, and what can go wrong, extraction quality will suffer.
What teams should monitor over the next 90 days
A documentation visibility project should not end with page edits. It needs observable checkpoints.
The most useful 90-day monitoring plan includes four layers:
- Crawl health: indexation status, sitemap coverage, redirect errors, and crawl anomalies
- Content accessibility: whether key answers appear in HTML and in consistent page sections
- Topic coverage: whether high-value developer questions have dedicated pages aligned to intent
- Visibility outcomes: impressions, rankings, citations, clicks, and conversion assists from docs traffic
This gives teams a grounded way to evaluate progress without inventing vanity metrics.
A realistic target is not “rank every docs page.” A realistic target is better coverage for commercially meaningful queries, cleaner extraction of high-value answers, and more qualified visits from documentation entrances.
That is also why documentation deserves a larger role in organic growth. In an AI-answer environment, brand becomes a citation engine. The documentation set that gets cited consistently is often the one that earns the click, the trial, and the trust.
FAQ: Technical SEO for developer documentation
What is technical SEO in the context of developer documentation?
Technical SEO for developer documentation means improving the site’s structure so search engines and AI systems can crawl, understand, index, and extract answers from docs pages. That includes crawlability, HTML accessibility, internal linking, canonical control, and clear content hierarchy.
Why would AI systems ignore documentation that already ranks in Google?
A page can rank for traditional search and still perform poorly in AI answers if the key information is hard to isolate. Common problems include weak headings, hidden content, duplicate versions, and pages that mix several intents together.
Do JavaScript-based documentation sites always hurt AI visibility?
Not always. The issue is not JavaScript itself but whether meaningful content is accessible and stable when crawlers process the page. If critical answers depend on delayed rendering or interaction, extractability usually gets worse.
Should every API endpoint have its own page?
Not every endpoint needs a standalone page, but every high-value query should have a clear destination. If one page covers too many endpoints or scenarios, both humans and AI systems may struggle to identify the exact answer.
How long does it take technical SEO fixes on docs sites to show results?
Basic crawl and indexation improvements can show up within a few weeks, especially after sitemap and canonical fixes. Stronger effects from structure, internal linking, and intent alignment usually take one to three months as crawlers revisit pages and visibility patterns stabilize.
A documentation estate that is easy to crawl, easy to parse, and easy to cite has a structural advantage in both search and A…