TL;DR
Technical SEO now affects whether SaaS help center content gets cited in AI answers, not just whether it ranks. The highest-impact fixes are clean architecture, crawl control, canonical ownership, task-based internal linking, and answer-first article formatting.
A SaaS help center is no longer just a support asset. It is now a source layer for AI answers, which means technical SEO decisions directly affect whether documentation gets crawled, understood, and cited.
The practical goal is simple: make help content easy for both search engines and AI systems to access, interpret, and trust. When that happens, the path improves from impression to AI answer inclusion to citation to click to conversion.
Why help center technical SEO now affects AI citations
Technical SEO for a help center is the work of making documentation easy to crawl, index, understand, and retrieve. In 2026, that matters not only for Google rankings but also for whether AI systems can confidently use the page as a source.
According to Semrush, technical SEO has evolved beyond traditional indexing concerns and now supports whether AI systems can crawl, render, index, and cite website content. That is the shift growth teams need to account for.
A concise rule explains the stakes: If AI systems cannot cleanly extract your help content, they are unlikely to cite it.
This is where many SaaS companies fall short. Their help center lives on a separate subdomain, duplicates product marketing pages, relies on weak internal linking, and leaves orphaned articles buried behind search boxes or faceted navigation. The content may be accurate, but the structure makes it harder to discover and harder to trust.
The business case is straightforward.
- Help center pages often answer high-intent product questions.
- Those questions are increasingly being handled inside AI-generated answers.
- The cited source often wins the click because it appears authoritative at the exact moment of need.
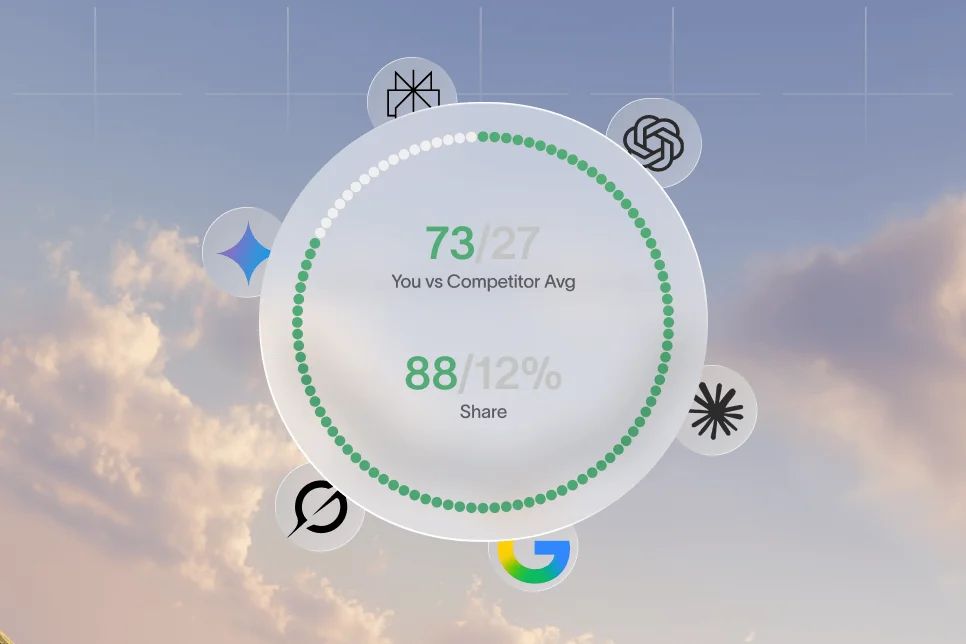
There is also a brand effect. In an AI-answer world, brand is a citation engine. Pages that are specific, consistent, and clearly structured are easier for AI systems to reference, and that repeated citation builds perceived authority over time.
Technical fixes alone do not solve everything. As Search Engine Land notes, technical SEO cannot compensate for weak intent alignment. A help article that is perfectly crawlable but answers the wrong question still performs poorly. The goal is technical accessibility plus relevance.
For teams building this into a broader content program, the work also overlaps with content scaling systems because documentation, templates, comparison pages, and educational content increasingly need to support one ranking model.
The help center structure that AI systems can actually use
Most help centers fail at structure before they fail at content. The issue is not article quality. The issue is whether the site makes hierarchy, page purpose, and relationships obvious.
A useful model is the crawl-extract-trust path.
- Crawl: bots and AI agents can find the page.
- Extract: the page is clean enough to parse quickly.
- Trust: the content looks specific, current, and authoritative.
That is not a gimmicky framework. It is a practical filter for every technical SEO decision.
Keep the hierarchy shallow and predictable
A help center should have a visible structure that moves from category to subcategory to article. Long, messy nesting creates crawl waste and weakens topical signals.
A clean structure looks like this:
- /help/account/
- /help/billing/
- /help/integrations/
- /help/security/
- /help/api-access/
Even when the underlying platform is Zendesk or Intercom, the information architecture still needs editorial control. Growth teams should not treat default help center templates as SEO strategy.
The practical test is simple. A reader and a crawler should be able to infer where a page sits in the product ecosystem within a few seconds.
Avoid fragmenting authority across subdomains without a reason
Many SaaS companies use support.example.com, docs.example.com, and www.example.com with minimal connection between them. That setup can work, but it often creates weak internal linking and inconsistent authority signals.
The contrarian position is this: Do not assume a separate docs subdomain is cleaner. In many cases, a tighter connection to the main domain is better for discovery and authority flow.
This does not mean every company must migrate. It means the burden of proof should be on fragmentation, not on consolidation. If the help center sits separately, teams should compensate with strong cross-linking, consistent taxonomy, and a shared sitemap strategy.
Make article purpose obvious above the fold
AI systems do not need visual design in the same way people do, but design still affects extraction. Cluttered templates create noise. Repetitive banners, oversized navigation blocks, and aggressive in-page widgets can dilute the main answer.
Each article should establish four things quickly:
- What problem it solves
- Which product area it belongs to
- Who it is for, if relevant
- When it was last updated
That format improves user confidence and gives AI systems a cleaner page to interpret.
Strengthen internal links around task completion
According to WebFX, internal links and site usability help engines understand page hierarchy. In a SaaS help center, internal links should not be treated as a footer exercise. They should model task progression.
For example, an article on resetting SSO should link naturally to:
- identity provider setup n- user provisioning
- common login errors
- admin permissions
- security requirements
That creates a map of related intent rather than a random cluster of “related articles.” It also increases the chance that an AI system sees the page as part of a coherent topic area instead of a standalone support note.
What to audit first: crawlability, indexing, and extraction hygiene
Technical SEO audits often become bloated. For help centers, the first pass should stay focused on whether AI systems and search engines can reliably reach and parse the right pages.
Start with robots.txt and XML sitemaps
As documented in Google Search Central, controlling crawler access through robots.txt and sitemaps is fundamental to SEO health. This matters even more for help centers because they often generate low-value tag pages, duplicate search result pages, and parameterized URLs.
Growth teams should review three things first:
- Whether important help articles are crawlable
- Whether thin or duplicate utility pages are blocked or de-emphasized
- Whether XML sitemaps include canonical, index-worthy help URLs
A common failure pattern is indexing internal search result pages while leaving high-value articles hard to discover through sitemap coverage. That reverses the priority.
Check canonical consistency across duplicate documentation
SaaS teams often duplicate content across onboarding docs, academy pages, blog tutorials, and support articles. Sometimes this is intentional. Often it is accidental.
If the same setup instructions exist in three places, AI systems may see conflicting versions. Search engines may split signals. Users may land on outdated pages.
The fix is not always consolidation, but every duplicated answer should have a canonical owner. That page should be the one that receives links, updates, and schema support.
Reduce template noise around the main answer
TechnicalSEO.com defines technical SEO through site and server configurations such as HTTP header responses and XML sitemaps. For help centers, the practical extension is extraction hygiene: pages should return correctly, load reliably, and surface the primary content without structural confusion.
That means teams should review:
- thin pagination pages
- broken breadcrumbs
- JS-heavy accordions hiding key answers
- repeated boilerplate at the top of every article
- popups or sticky modules that dominate the DOM before the article body
Not every one of these issues blocks ranking. But together they make extraction less clean, especially for large help centers where AI systems have many similar pages to choose from.
Use a focused action checklist before deeper fixes
A first-round checklist should fit on one page. That keeps the audit tied to outcomes instead of turning into a technical backlog with no prioritization.
- Confirm help articles are crawlable in robots.txt.
- Verify XML sitemaps list only canonical, index-worthy help URLs.
- Remove or noindex internal search results, filters, and duplicate utility pages.
- Fix broken breadcrumbs and weak category paths.
- Add contextual internal links between articles that solve adjacent tasks.
- Make sure each article has one clear H1, one primary answer block, and an updated date.
- Check that canonical tags point to the preferred version.
- Reduce template elements that push the main answer too far down.
- Track which help articles already earn impressions and citations.
- Refresh outdated pages before publishing new duplicates.
This is also where teams should establish a baseline. Useful measurements include indexed help URLs, organic clicks to help content, impressions for product-question queries, and citation presence in AI tools during a recurring manual review.
For teams treating this as an ongoing process rather than a one-time cleanup, a structured refresh workflow helps prevent decay from eroding visibility after the initial gains.
How to format help articles so they are easier to cite
Citations are not won by technical SEO alone. They are won when technical SEO supports pages that answer questions clearly and consistently.
Write the answer first, then the detail
The opening of a help article should state the answer in plain language before steps, screenshots, or edge cases. This makes the page more useful to readers and more extractable for AI systems.
A weak opening says: “This article will walk through several settings available within the admin interface.”
A stronger opening says: “To enable SAML SSO, an admin must add the identity provider metadata, verify the domain, and test login before enforcing the policy.”
That second version is more citable because it is precise and self-contained.
Use headings that reflect real user tasks
SERP patterns around technical SEO show strong informational intent and question demand. Help center headings should reflect the same behavior.
Good headings include:
- How to export audit logs
- Why SSO login keeps failing
- Where to change invoice recipients
- What admin permissions are required for SCIM
Bad headings include:
- Authentication settings overview
- Billing workflows documentation
- User management article 4
Task-driven headings improve retrieval and reduce ambiguity.
Add context that increases trust
AI systems are more likely to cite pages that feel trustworthy and uniquely useful. In practice, that means documentation should include concrete qualifiers such as plan limitations, prerequisites, permissions, and expected outcomes.
For example:
- “Available on Pro and Enterprise plans”
- “Requires workspace admin permissions”
- “Changes take effect on the next sync cycle”
- “This setting does not retroactively update historical exports”
These details matter because they make the answer specific. Generic support content is harder to trust and easier to replace.
Use examples that remove ambiguity
A help center page should contain screenshot-worthy detail even when no screenshot is embedded in the article body.
Consider a before-and-after documentation rewrite:
- Baseline: “Configure your webhook endpoint in the integrations page.”
- Intervention: Rewrite the intro to specify where the setting lives, what event types are available, who can access it, and what confirmation looks like after setup.
- Expected outcome: Better retrieval for product-specific questions, cleaner support intent matching, and higher citation potential for setup-related AI answers.
- Timeframe: Review within 30 to 45 days using query impressions, assisted clicks, and recurring AI answer checks.
No fabricated numbers are needed. The proof is in the measurement plan and the reduction of ambiguity.
Pair technical SEO with structured page consistency
A help center does not need to read like a blog. But it does need repeatable page structure. Teams should keep article templates consistent across key elements:
- answer summary
- prerequisites
- steps
- edge cases
- related tasks
- last updated date
That consistency improves editorial speed and supports extraction.
A platform like Skayle fits into this work when teams need one system to plan, optimize, and maintain pages that rank in search and appear in AI answers. The value is not content volume by itself. The value is measurable visibility, cleaner execution, and fewer gaps between publishing and performance.
Common technical SEO mistakes that block citations
Most help center problems are not dramatic. They are accumulations of small decisions that make documentation harder to crawl, harder to interpret, or less trustworthy.
Publishing every utility page into the index
Search boxes, tag pages, filters, and paginated collections often end up indexed by default. This creates noise and can pull attention away from core articles.
The better approach is selective indexation. Not every reachable URL deserves to compete for crawl attention.
Letting the search box replace navigation
Many support teams rely on internal site search instead of fixing navigation. That may be acceptable for users already on the site, but it is weak for discoverability.
If a useful article can only be found through the search box, its crawl path is probably underdeveloped.
Keeping outdated versions live without ownership
Outdated migration guides, legacy UI screenshots, and deprecated setup instructions weaken trust fast. AI systems may still retrieve them if they remain crawlable and internally linked.
Every product area needs an owner responsible for retiring, redirecting, consolidating, or refreshing old help content.
Writing support content with no commercial awareness
This is another contrarian point. Help centers should not be stuffed with conversion CTAs, but they should recognize where support intent overlaps with buying intent.
A page about SSO, audit logs, or role-based permissions often serves both current users and evaluators comparing vendors. That means documentation quality can influence pipeline, not just ticket deflection.
The design implication is subtle: pages should make plan availability, product scope, and related capability paths visible without turning the article into a sales page.
Treating technical SEO as a one-time project
Help centers change constantly. New features ship. Navigation evolves. CMS settings break. Documentation teams reorganize categories. A one-off cleanup rarely holds.
That is why recurring audits matter, especially for AI visibility. Teams already paying attention to citations can go deeper with an AI visibility audit to understand where their brand appears across answer engines and where documentation is underrepresented.
How growth teams should measure success after the cleanup
The right measurement model is broader than rankings. A help center built for AI citation should be evaluated across the full path from visibility to business impact.
Track the full funnel, not just page sessions
The most useful view is:
- Impression
- AI answer inclusion
- Citation
- Click
- Conversion or assisted conversion
Some of these signals are still imperfect to measure directly, but a practical reporting stack can still be built.
Use:
- Google Search Central guidance for crawl and indexing diagnostics
- Google Analytics for downstream engagement and assisted conversions
- Google Search Console for impressions, clicks, and query classes tied to help content
If the help center supports product evaluation queries, teams should also segment visits from branded and non-branded informational searches and compare assisted conversion behavior over time.
Use page groups instead of isolated article reporting
Individual help articles can be volatile. Product changes create spikes, and support demand shifts quickly. Reporting by page group is often more useful.
Examples include:
- billing and pricing operations
- security and compliance
- integrations and setup
- admin configuration
- troubleshooting and errors
This helps identify which topic areas are becoming stronger source layers for AI answers.
A realistic proof block for the first 60 days
A practical measurement plan looks like this:
- Baseline: indexed help URLs, clicks from help content, top query classes, and a manual record of whether core pages are cited by major AI assistants for ten to twenty product questions.
- Intervention: fix crawlability, consolidate duplicates, strengthen task-based internal links, rewrite answer-first intros, and refresh outdated high-intent articles.
- Expected outcome: more stable indexing, better query alignment, stronger engagement on help content, and improved citation presence for product-specific answers.
- Timeframe: review at 30, 60, and 90 days.
This is disciplined technical SEO. It ties site structure to measurable authority instead of treating support content as an isolated library.
Five questions teams ask before reorganizing a help center
What is technical SEO in a SaaS help center?
Technical SEO in a SaaS help center means making documentation easy for search engines and AI systems to crawl, index, understand, and cite. That includes site structure, internal linking, canonical control, crawl access, and reducing template noise around the main answer.
Should a help center live on a subdomain or subfolder?
Either can work, but the decision should be based on authority flow, operational simplicity, and internal linking quality. A separate subdomain is not automatically better, and many teams underestimate the visibility cost of fragmented architecture.
Do AI systems use help center content differently from blog content?
Often yes. Help center content tends to be more task-specific, product-grounded, and citation-friendly when written clearly. That makes it useful for AI answers, especially when a user asks how a feature works or how to solve a known product problem.
Does technical SEO matter if the help articles are already ranking?
Yes. Rankings do not guarantee clean extraction or citation. Pages can perform reasonably in search while still being weakened by duplicate versions, cluttered templates, weak internal links, or outdated content.
What should be fixed first in a large help center?
Start with crawl access, sitemap quality, canonical consistency, and article hierarchy. After that, focus on answer-first intros, internal links between related tasks, and consolidating duplicate or stale content.
A well-structured help center becomes more than documentation. It becomes a durable source layer for search, AI answers, and high-intent product discovery.
Teams that want a clearer view of where their documentation stands can measure AI visibility, understand citation coverage, and build a more reliable publishing system around technical SEO rather than guessing which pages are…