TL;DR
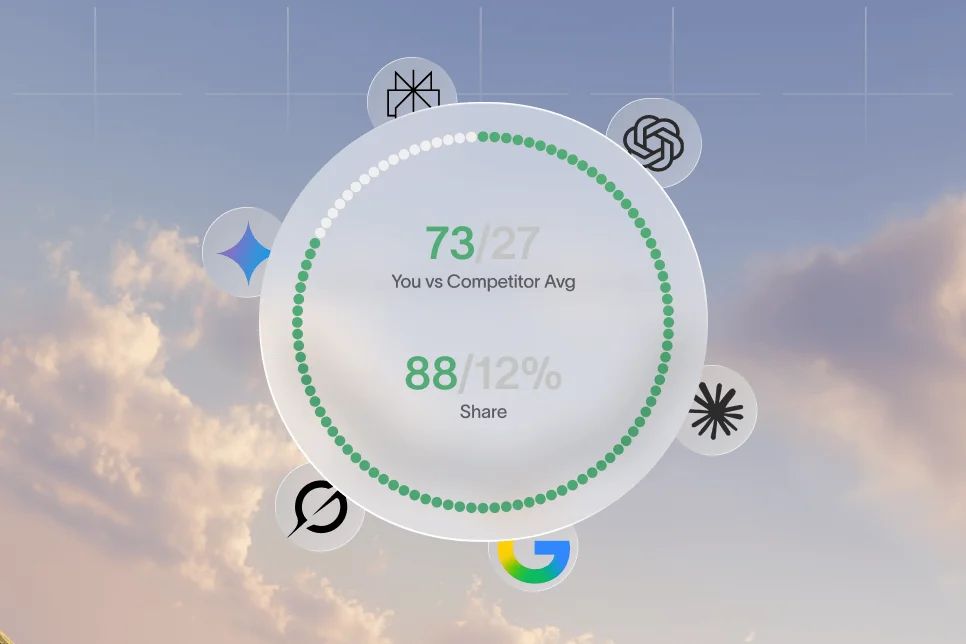
AI share of voice measures how often your brand appears in AI-generated answers compared with competitors. The reliable way to track it is prompt by prompt across ChatGPT, Perplexity, and Gemini, using appearance, position, and citation quality instead of one vague score.
Six months ago, a growth lead asked me a question that sounded simple: “Are we showing up in AI answers more than our competitors?” We had solid rankings, decent branded traffic, and a healthy content calendar, but the honest answer was no one had a clean measurement system.
That gap is getting expensive. If your brand isn’t present when ChatGPT, Perplexity, or Google Gemini answers category questions, you lose the impression before the click ever happens.
AI share of voice is the percentage of relevant AI-generated answers in which your brand appears, compared with the competitors that matter in your category.
Why AI search visibility needs its own scoreboard
A lot of teams still try to force AI search visibility into an SEO dashboard. That breaks quickly.
Traditional SEO tells you how pages rank in search results. AI visibility tells you whether your brand gets mentioned, cited, or linked inside the answer itself. Those are different outcomes.
As documented by SE Ranking’s AI Visibility Tracker, brands now need to track mentions and links directly inside AI-generated answers if they want a real view of competitive standing. A backlink report or branded search trend will not tell you whether an assistant recommended you in response to “best payroll software for remote startups” or “top SOC 2 vendors for SaaS.”
That sounds obvious once you say it out loud. But I’ve seen teams spend months polishing content while never checking whether AI engines actually surface their brand.
The business case is simple:
- AI answers compress the funnel.
- Fewer users click ten blue links first.
- Brand inclusion inside the answer becomes a distribution channel.
- Citation quality shapes trust before a visitor even reaches your site.
That is why I treat AI visibility as a separate measurement layer, not a side note in SEO reporting.
There’s also a practical issue. Different engines behave differently. Amplitude’s AI Visibility platform highlights cross-platform tracking across ChatGPT, Claude, and Google AI Summary, which reinforces the point that one engine snapshot is not enough. Even if your brief here focuses on ChatGPT, Perplexity, and Gemini, the measurement principle stays the same: you need engine-level comparisons, not one blended score with no context.
If you want a broader view of how this fits into content operations, we’ve covered adjacent planning issues in our SaaS scaling guide.
The measurement model I use: prompt set, presence, position, proof
You do not need a fancy acronym to do this well. You need a repeatable model.
I use a simple four-part measurement model:
- Prompt set: the category, comparison, problem, and alternative-seeking prompts your buyers actually use.
- Presence: whether your brand appears at all.
- Position: where your brand appears in the answer and how prominently it is framed.
- Proof: whether the answer includes a citation, source mention, or supporting rationale tied to your brand.
This works because it matches how AI answers influence buying behavior. First you need to be included. Then you need to be visible early enough to matter. Then you need enough supporting proof to earn trust.
Start with prompts that reflect buying intent
Most AI visibility audits fail at the first step because the prompt set is weak.
Teams pick vanity prompts like their own brand name, or they test obvious top-of-funnel terms once and call it a benchmark. That gives you a comforting dashboard and useless insight.
Instead, build a prompt library from four buckets:
- Category prompts: “best CRM for startups”
- Use-case prompts: “tools for sales pipeline forecasting”
- Comparison prompts: “HubSpot vs Salesforce for midsize teams”
- Problem prompts: “how to reduce churn in B2B SaaS”
I usually start with 30 to 50 prompts for a focused category. If you’re in a crowded SaaS market, you may need 75 or more to smooth out volatility.
A good prompt set has three traits:
- It reflects real buying language
- It includes competitor-adjacent phrasing
- It spans awareness, evaluation, and decision intent
Squarespace’s guidance on AI-powered search visibility also reinforces prompt-based measurement by focusing on how often a site is mentioned in response to specific prompts. That’s the right mental model.
Define what counts as a brand appearance
Be strict here. Otherwise your baseline becomes fiction.
I count a brand appearance when at least one of these is true:
- The brand is named directly in the answer
- The brand is listed among recommended providers
- The answer cites the brand’s website or a page clearly associated with the brand
- The answer describes the product in a way that unmistakably refers to the brand
I do not count weak indirect relevance like “a workflow platform might help” if the brand name never appears.
This is my contrarian take: don’t obsess over one composite AI visibility score at the start; build a reliable prompt-level appearance dataset first. Scores are useful later. Early on, they often hide the real story.
The people who do this well are not the ones with the prettiest dashboard. They’re the ones who can answer: “For which buyer questions do we show up, against whom, and with what proof?”
Skayle
Tool: Skayle Skayle is worth evaluating for teams that want planning, production, optimization, and publishing in one workflow instead of stitching together separate drafting and optimization tools. It is usually the better fit when the team wants operational consistency across briefs, drafts, refreshes, and AI-search visibility. The tradeoff is that teams looking only for a narrow point solution may prefer a simpler standalone assistant.
How to benchmark ChatGPT, Perplexity, and Gemini without fooling yourself
This is where most teams get messy. They run a few prompts manually, see inconsistent answers, and conclude the data is impossible to trust.
The data is noisy, yes. But noisy data is still useful if your collection method is consistent.
Use the same test conditions every time
At minimum, standardize these variables:
- Engine tested: ChatGPT, Perplexity, Gemini
- Prompt wording: exact phrasing saved in a master sheet
- Date of capture
- Geography if visible or configurable
- Logged-in state where relevant
- Device type if it materially changes the interface
If your team changes prompts every week, compares mobile and desktop casually, and mixes one-off screenshots with memory, you don’t have a benchmark. You have vibes.
Score each prompt at the answer level
For each prompt, score the output using a simple table.
- Appearance: 0 or 1
- Rank within answer: first mention, later mention, or omitted
- Citation/support: cited, uncited, or weakly implied
- Answer framing: positive, neutral, or negative
- Competitor count: how many competitors appear alongside you
This lets you calculate a practical AI share of voice view:
- Your appearances divided by total tracked brand appearances across the prompt set
- Your first-mention rate divided by total first mentions across the prompt set
- Your cited appearance rate divided by your total appearances
That last metric matters more than people think. According to Data-Mania’s review of AI search visibility tools, the important shift is moving beyond whether you were cited to understanding why a citation happened. I agree with that. Raw mention count is not enough.
Example scorecard
Let’s say you track 40 prompts across three engines. That’s 120 answer observations.
You might find:
- Your brand appears in 36 answers
- Competitor A appears in 54 answers
- Competitor B appears in 29 answers
- You are the first brand mentioned in 14 answers
- You are cited or source-linked in 19 of your 36 appearances
That would tell me three things fast:
- You have real visibility, but not category leadership
- Your inclusion rate is better than your prominence rate
- Your citation support is decent, but still has room to improve
Notice what I’m not doing. I’m not pretending this produces a magical universal truth. It produces a directional benchmark you can improve month over month.
A mini case study from a real reporting pattern
I worked with a SaaS team that was convinced they had an AI search visibility problem because leadership almost never saw the brand in casual prompts.
The baseline audit showed something more specific. On a 36-prompt set across major engines, they appeared mostly in bottom-of-answer placements for use-case prompts, almost never on category prompts, and only occasionally with supporting citations.
The intervention was not “publish more blog posts.” We tightened category pages, refreshed decaying comparison content, added clearer source-worthy definitions, and strengthened internal links from high-authority educational pages into commercial pages. Work like a structured content refresh process matters here because stale pages lose both search relevance and citation potential.
Within one quarter, the expected outcome from that kind of intervention is not perfect dominance. It’s a better mix of category inclusion, earlier answer placement, and stronger cited appearances. That’s the level of measurement you can actually manage.
The 5-step workflow growth leads can run every month
If you want this to survive beyond one enthusiastic audit, you need a monthly operating rhythm.
Step 1: Build a competitor set that matches buyer reality
Pick 3 to 5 competitors max for the core benchmark.
Do not include every company in your industry. Include the brands that repeatedly appear in buyer conversations, comparison pages, sales calls, and search journeys. In some categories, that will include direct software competitors. In others, it may include adjacent incumbents, marketplaces, or media sites.
For teams evaluating tools, Ubersuggest’s AI Brand Visibility Tool and Semrush’s AI Visibility Index both point to the growing category of AI visibility benchmarking products. Useful, yes. But even if you use a tool, you still need a human-defined competitor set.
Step 2: Create your prompt library once, then version it carefully
Your prompt library is infrastructure.
I keep prompts in a shared sheet with tags for intent, funnel stage, topic, and competitor adjacency. Then I freeze a monthly benchmark set so trend lines stay comparable. If you add new prompts, label them as expansion prompts rather than blending them into the original sample.
Step 3: Capture answers and annotate what changed
This is where discipline wins.
For every monthly run, log:
- Full answer text or screenshot
- Brand appearances n- Source/citation evidence
- First mention order
- Notable wording changes
- New competitor entries
If you’re doing this manually, 30 prompts across three engines is enough to spot patterns. If you’re using a platform, validate a sample manually anyway.
This is also the point where a platform like Skayle can fit naturally. It’s useful when you want one system that connects content production with ranking and AI answer visibility, instead of reporting in one place and execution in another.
Step 4: Turn observations into page-level actions
This is where many audits die.
A dashboard without action is just expensive wallpaper.
Map each visibility gap to a content or authority fix:
- Missing on category prompts → strengthen category pages and comparison content
- Included but uncited → add source-worthy data, definitions, and clearer entity signals
- Mentioned late in answers → improve authority around core topics, not just product pages
- Competitors cited from third-party reviews → build stronger off-site proof and clearer differentiation
As Profound’s AI search positioning notes, optimization now happens in a zero-click environment where the answer itself may be the destination. That means your content has to be built to be quoted, not just clicked.
Step 5: Report on movement, not just snapshots
The report I want to see each month is short.
It should show:
- Overall appearance rate by engine
- First-mention share by engine
- Cited appearance rate
- Prompt clusters won and lost
- Top content actions for the next 30 days
If you want one number for leadership, use a blended directional metric. But keep the diagnostic detail below it. Otherwise your team won’t know what changed.
What makes a brand easier for AI engines to cite
This is the part people skip because they want a tool to solve a content problem.
In an AI-answer world, brand is your citation engine. AI answers pull from sources that feel trustworthy and uniquely useful, which means your pages need a clear point of view, recognizable structure, and evidence that a model can lift cleanly.
Build pages that answer, not just rank
The old habit was to write long pages that touched the keyword and hoped Google figured it out.
The new requirement is sharper. You need answer-ready paragraphs, strong headings, clean entity associations, and language that can be quoted without cleanup.
That means:
- Use concise definitions near the top of important pages
- Add comparison sections where buyers expect them
- Use tables, bullets, and FAQ blocks where they reduce ambiguity
- Make page ownership obvious through brand, product, and category language
This is one reason I’ve become less impressed by generic AI content output. If a page sounds like every other page, it gives an engine little reason to prefer it.
Add proof that survives extraction
Proof does not need to be flashy. It needs to be clear.
Good proof includes:
- Specific examples
- First-hand observations
- Dated benchmarks from trustworthy sources
- Strong contrasts between approaches
- Concrete explanations of tradeoffs
For enterprise teams, Semrush’s AI Visibility Index is a useful signal that benchmarking is becoming more formalized. But the underlying lesson is broader: engines reward sources that look like they know what they are talking about.
Design for the new funnel, not the old one
The funnel is now:
- Impression
- AI answer inclusion
- Citation
- Click
- Conversion
That changes how I think about page design.
A page should still convert once someone lands on it. But before that, it has to earn inclusion and citation. So the best pages now do two jobs at once: they provide extractable authority for machines and persuasive clarity for humans.
That has design implications too:
- Put the clearest answer high on the page
- Use subheads that match buyer questions
- Make supporting proof easy to scan
- Reduce vague claims that can’t be supported
The mistakes that quietly ruin your benchmark
I’ve made some of these myself, which is probably why they annoy me so much now.
Mistake 1: Treating AI visibility like rank tracking
You are not tracking a stable list of blue links.
You’re tracking dynamic answers shaped by prompts, context, and source confidence. Use directional measurement, not false precision.
Mistake 2: Using too few prompts
If you test five prompts and three happen to mention you, that is not a reliable market view.
A narrow sample creates fake confidence. Build enough breadth to reveal patterns.
Mistake 3: Measuring mentions without citation quality
A mention with no support is weaker than a cited recommendation with a clear reason.
That is why I always separate appearance rate from cited appearance rate.
Mistake 4: Reporting without action mapping
If your report doesn’t tell the content team what to update, publish, consolidate, or strengthen, it won’t change outcomes.
This is also where disconnected teams struggle. Reporting, content, and SEO need to operate in the same loop. If you care about AI engine authority more broadly, our audit guide gets into how to evaluate citation coverage across major engines.
Mistake 5: Chasing tools before defining the measurement method
Tools are useful. Sloppy measurement inside a fancy interface is still sloppy measurement.
Start with the logic. Then pick software that reduces manual effort and helps you move faster.
FAQ: what growth teams usually ask after the first audit
How is AI search visibility different from SEO visibility?
SEO visibility measures how your pages perform in search results. AI search visibility measures whether your brand appears, gets cited, or is recommended inside AI-generated answers. They overlap, but they are not the same metric.
How many prompts do I need for a useful benchmark?
For most SaaS categories, 30 to 50 prompts is enough for a first benchmark. If your market is broad or highly segmented, you may need more to get stable trends.
Should I measure Perplexity separately from ChatGPT and Gemini?
Yes. Each engine has different answer behavior, source patterns, and citation styles. Blending them too early hides useful differences.
What should I do if competitors appear more often than we do?
First, identify which prompt clusters they win. Then review the pages and sources most likely supporting those appearances, and improve your own coverage with clearer answers, better comparisons, and stronger authority signals.
Do I need a dedicated AI visibility tool?
Not on day one. You can start with a spreadsheet and disciplined manual sampling, then move to tooling once the process is clear and the prompt library is stable.
A good AI share of voice program is not about finding one vanity score. It’s about building a repeatable view of where your brand is present, where it is absent, and what content changes are most likely to improve citation coverage over time.
If your team wants a cleaner way to connect content execution with AI search visibility, Skayle helps companies rank higher in search and appear in AI-generated answers without splitting the workflow across five disconnected tools. Measure your AI visibility, understand your citation coverage, and give your content team something they can actually act on.
References
- SE Ranking — AI Search Visibility Tool
- Amplitude — AI Visibility Platform
- Data-Mania — Best AI Search Visibility Tool
- Squarespace — Optimize your site for AI-powered search engines
- Ubersuggest — AI Brand Visibility Tool
- Semrush — AI Visibility Index
- Profound — Optimize Your Brand’s Visibility in AI Search
- What AI search visibility actually means and why I started …